











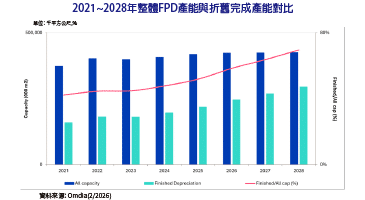
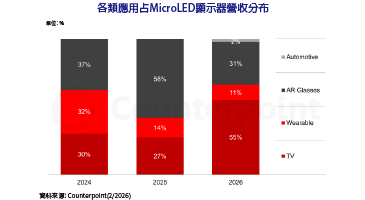
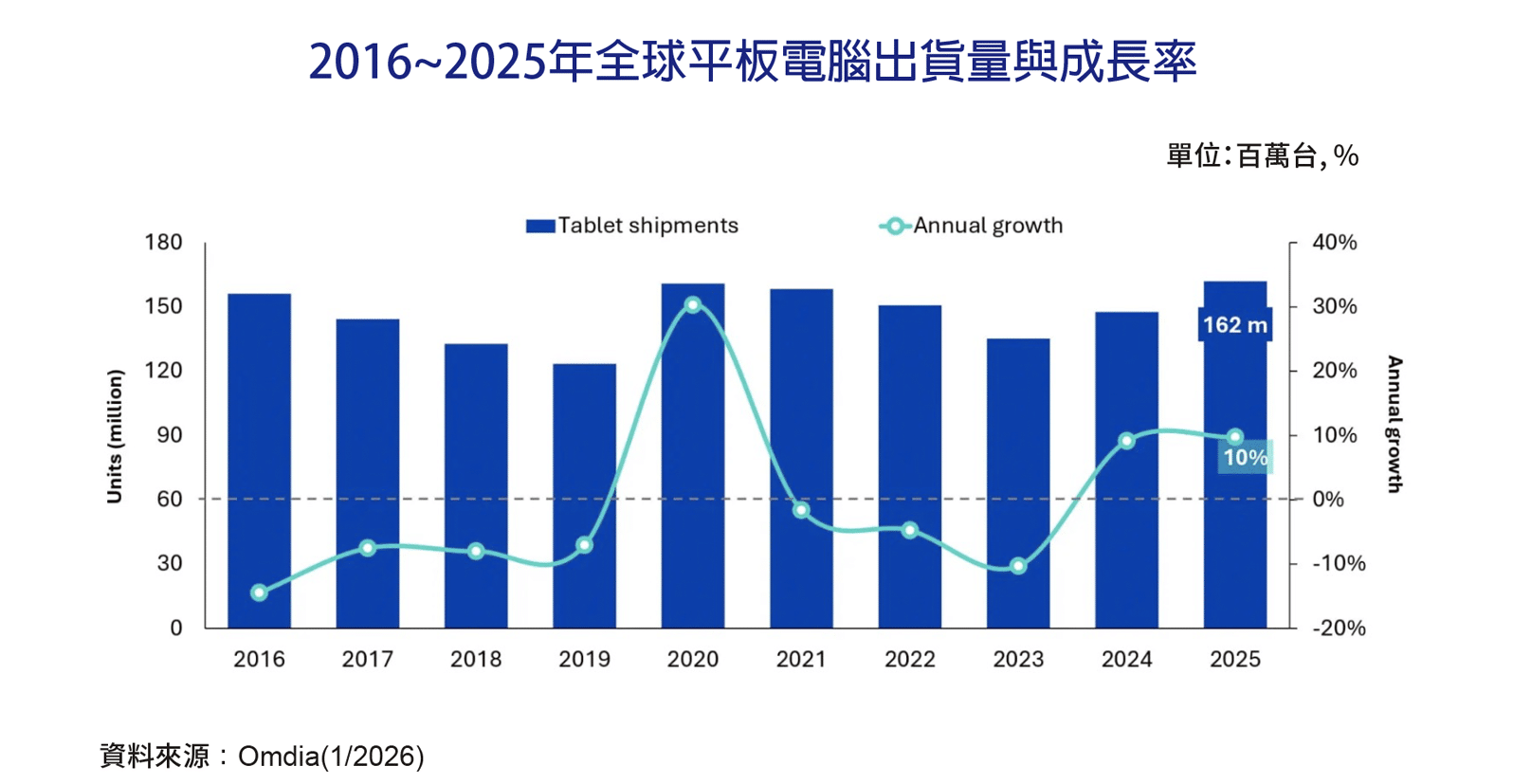
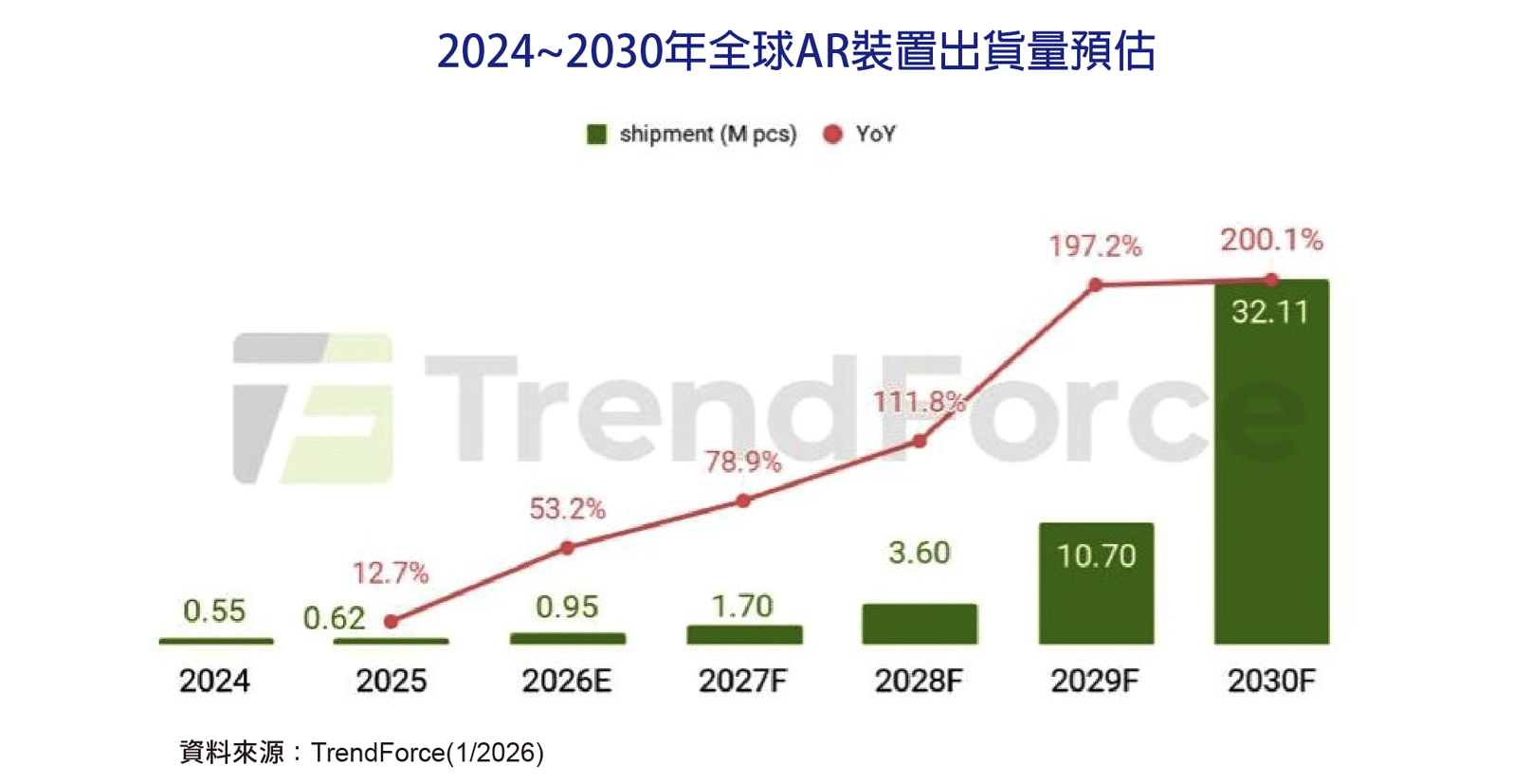





耐能宣布推出新一代NPU晶片KL1140,全面構建從終端到雲端的AI基礎設施版圖。該NPU是全球第一款可以支援Mamba神經網路的NPU,其能源效率是現有雲端方案的3倍,成本則下降10倍。

耐能創辦人暨執行長劉峻誠表示,當前以GPU為基礎的AI硬體設備雖具有強大的算力,但耗電量太大,不利於環境永續,成本也偏高。因此,業界始終在尋找能源效率更好、成本更低的解決方案。耐能率先提出的NPU,在功耗、成本上具有先天優勢,因此,NPU的概念提出後,許多國際晶片大廠如英特爾(Intel)、超微(AMD)、高通(Qualcomm)等,也都投入相關技術研究,並推出自己的NPU產品;Google的TPU也有許多與NPU相似的特性。這個客觀事實證明,在AI運算領域,NPU有其獨特的利基存在。
作為NPU領域的先行者,耐能也在持續發展新的NPU。KL1140與後續將推出的一系列高階NPU晶片,就是耐能持續研發的成果。KL1140可以直接在邊緣設備上運行大型模型,讓大語言模型(LLM)能真正走入終端。該晶片是專為語音理解、自然語言處理、智慧視覺、機器人等應用而設計,其典型應用包含智慧監控、車載系統、企業私有AI助理及智慧製造。而且,KL1140很容易擴展,藉由並聯4顆KL1140 NPU,就能運行120B參數模型,且功耗只有GPU的三分之一。
除了發表新一代旗艦產品,耐能也展示了相關應用的開發成果,顯示該公司已不僅是一家晶片供應商,而是全端(Full-stack) AI基礎建設的供應者。劉峻誠表示,目前該公司提供的應用方案,是由晶片、客製化模型與應用程式所組成,涵蓋的垂直領域則包含醫療、教育、企業與主權AI。同時,耐能也藉由購併台達電旗下子公司跟對義大利伺服器製造商Spark進行策略投資,進一步擴大對各垂直領域的布局。
至於在核心技術的突破方面,劉峻誠則指出,對Mamba神經網路的支援,是該公司研發團隊最重要的突破。從耐能創立至今,AI的底層核心技術已經歷過一次重大革命,也就是從卷積神經網路(CNN)到Transformer的過渡。如今最流行的各種生成式AI模型,底層都是Transformer。但Transformer並不完美,其上下文長度與執行速度,都有可以改善的空間。Mamba架構就是針對這些提出其改良,藉由採用狀態空間(State Space)機制而非注意力(Attention)機制,來提升模型運作的效率。
但也因為Transformer跟Mamba有許多根本上的差異,因此,要設計出一款可以支援Mamba的處理器或加速器,需要投入可觀資源,同時也要承擔一定的風險。對此,劉峻誠認為,耐能高度彈性的運算架構設計,使得該公司可以承擔更多創新風險。耐能的第一款NPU是為CNN加速而設計,但在Chatgpt還沒爆紅前,耐能就已經領先業界,推出第一款可以支援Transformer的NPU,關鍵也在於耐能使用的運算架構,是非常彈性的。這次,耐能再度領先業界,推出可支援Mamba網路的加速器,也是得益於此。考慮到Mamba網路優異的執行效率,耐能相信,Mamba會是下一個值得押寶的目標。





